Jak wspomniałem w poptrzednim wpisie na ten temat, zadanie polega na znalezieniu takich działań, które wstawione pomiędzy liczby dadzą równianie. Czytaj...
Zainspirowany pewną zagadką, którą otrzymałem na interview napisałem aplikację, która pozwoli obniżyć poziom stresu przynajmniej do momentu, aż rekturerzy znajdą Czytaj...
O kopiowaniu plików, którego nie zaskoczy shut down serwera. Czytaj...
Co to takiego?
Domyślamy się, że aplikacja może w jakiś sposób udostępniać informację o swoim stanie. Takie kontrole stanu mogą być użytecznymi mechanizmami zarówno dla aplikacji monolitycznych, jak i mikrousług. W przypadku aplikacji „na produkcji” często pojawia się nawet oczekiwanie, aby „jakoś” monitorować co w kodzie szeleści i czy aby nie piszczy albo gorzej – zgrzyta. Wtedy na ogół patrzymy sobie na logi, albo obrazki na Grafanie. Bardziej zaawansowani generują maile z alertami. Czasem trochę po partyzancku, „aby coś tam było”.
Aż tu pewnego dnia IT zażądało kontroli stanu aplikacji na klastrze. Wymyślili sobie, że skoro Kubernetes pozwala sprawdzić czy aplikacja wciąż działa i jak działa, to chcieliby, żeby backend zaimplementował taką kontrolę stanu. Nie rozpisując sie tu o tym, jakie zaprojektowali działania, kiedy ten stan nie będzie zadowalający, powiem tylko, że rozgorzała dyskusja ile to z tym będzie roboty. Niby rzecz prosta, ale okazało się, że to niecodzienne żądanie IT rozgrzało głowy. Żeby jakoś temat ogarnąć po stronie backendu .NETowego, zrobiłem instrukcję na firmowym conflu, którą tu bez zbędnej zwłoki przytoczę.
Rodzaje kontroli stanu push i pull
Kontrola stanu może przebiegać w dwóch kierunkach: albo kontrolowany system periodycznie raportuje swój stan do systemu monitorującego bez pytania. To nazywa się heartbeat lub push. Działa nawet za NAT czy firewallem, ale brak aktywności może oznaczać zarówno awarię, jak i problem z siecią.
Drugi sposób określany jako pooling lub pull, polega na tym, że aplikacja odpowiada na żądanie systemu monitorującego. Warunek − aplikacja musi być osiągalna sieciowo.
Kubernetes, load balancery mają wbudowany mechanizm badania stanu przez wysłanie żądania do aplikacji – pull. Można odpytać aplikację czy żyje (odpowiada) – liveness probe. Jeśli apka nie odezwie się, to pod zostanie ubity i postawiony na nowo z nadzieją, że to załatwi problem. Wersja zaawansowana to dodatkowa kontrola podsystemów aplikacji – readiness probe. Taki test powinien sprawdzić, czy wszystkie żywotne usługi działają poprawnie (czy baza odpowiada w skończonym czasie, czy odbierane są zdarzenia z Kafki itd).
Kontrola stanu w ASP.NET
Od .NET6 mamy w pełni funkcjonalny mechanizm health check w postaci endpointów http, czyli system pull. Myślę, że lepiej jest pokazać działający kod niż opowiadać albo pokazać zrzut ekranu, dlatego od razu będzie przykład działającej aplikacji. Przykład będzie w .NET10. Wyprodukujemy aplikację, która udostępni dedykowane endpointy. Ich odpytanie uruchomi testy a one zwrócą rezultat użyteczny dla systemu monitorującego.
Struktura aplikacji
Żeby pozostać w trendzie, użyję Clean Architecture. W listingach będą podane przestrzenie nazw namespace. Gdyby ktoś chciał wykonać przykład razem ze mną (do czego zachęcam), to łatwo będzie umiejscowić kod u siebie.
Niezbędne składniki
Przepis na healthchecki jest następujący:
Zaimplementuj IHealthCheck dla każedgo testu, jaki ma być uruchomiony
Zaimplementuj odpowiednie serwisy w warstwie Infrastructure
Zmapuj testy do endpointów
Zarejestruj serwisy w DI
Skonfiguruj aplikację
Czas na implementację. Na początek utwórz katalog i nową „pustą” aplikację asp.net
mkdir ./healthchecks
cd healthchecks
dotnet new web
Mapowanie
To nie jest pierwszy składnik w przepisie, ale trochę wyjaśnia co i dlaczego za chwilę wykonamy.
Tu dzieją się dwie rzeczy: tworzone są endpointy oraz mapowane są testy. Zapytanie /health/ready uruchomi testy zawierające tag „ready”. Są to testy sprawdzające, czy aplikacja jest gotowa do pracy wraz ze wszystkimi niezbędnymi składnikami. Takich składników jest więcej niż jeden, dlatego szukamy wszystkich otagowanych „ready”. Test liveness probe pod adresem /health/live jest dużo prostrzy i jest jeden. Mapuję go według nazwy „live”.
namespace Infrastructure.HealthChecks.Extensions;
public static class WebApplicationExtensions
{
public static void MapAppHealthChecks(this WebApplication app)
{
app.MapHealthChecks("/health/ready", new HealthCheckOptions
{
Predicate = check => check.Tags.Contains("ready")
});
app.MapHealthChecks("/health/live", new HealthCheckOptions
{
Predicate = check => check.Name == "live"
});
}
Implementacja health checków
Na początek potrzebne modele.
namespace healthchecks.Infrastructure.Persistence.DataModels;
public class DbHealthStatus
{
public HealthStatus Status { get; set; }
public double ResponseTime { get; set; }
public string Message { get; set; } = null!;
public DateTime SystemTime { get; set; }
public string? UserName { get; set; }
public string? SessionId { get; set; }
}
public enum HealthStatus
{
Critical,
Error,
Slow,
Ready
}
Test bazy danych polega na uruchomioniu procedury, która wykona proste obliczenia i zwróci czas, nazwę użytkownika i komunikat, w którym określi swój stan.
Implementacja testu bazy danych (interfejsu IHealthCheck) polega na uruchomieniu przez serwis IDbStatusService procedury składowanej i interpretacji zwróconych danych. Jeśli baza danych jest w pełni sprawna, to żądanie GET: /health/ready zwróci kod 200 i tekst Healthy w body odpowiedzi. Jeśli baza będzie spowolniona, to dostaniemy 200 z tekstem Degraded. W przypadku awarii bazy (w domyśle chwilowej) dostaniemy 503 z opisem Unhealthy. Status 503 to kod błędu transient, czyli takiego, po którym możemy oczekiwać, że za wkrótce samoczynnie ustąpi. Kubernetes może w takim przypadku odciąć takipod od puli sprawnych i spróbować podłączyć po chwili.
using DbStatus = healthchecks.Infrastructure.Persistence.DataModels;
namespace healthchecks.Infrastructure.HealthChecks;
internal class DatabaseHealthCheck(IServiceScopeFactory scopeFactory) : IHealthCheck
{
public async Task CheckHealthAsync(HealthCheckContext context, CancellationToken ct = default)
{
try
{
using var scope = scopeFactory.CreateScope();
var dbStatusService = scope.ServiceProvider.GetRequiredService();
var result = await dbStatusService.GetStatus(ct);
return result.Status switch
{
DbStatus.HealthStatus.Ready => HealthCheckResult
.Healthy("Database connected"),
DbStatus.HealthStatus.Slow => HealthCheckResult
.Degraded("Database connected, but response is slow"),
_ => HealthCheckResult.Unhealthy("Database check failed"),
};
}
catch (Exception ex)
{
return HealthCheckResult.Unhealthy("Database connection failed", ex);
}
}
}
Serwis IDbStatusService
Potrzebny jest inrerfejs
namespace healthchecks.Infrastructure.HealthChecks.Interfaces;
public interface IDbStatusService
{
Task GetStatus(CancellationToken ct);
}
Nasz DatabaseHealthCheck woła metodę IDbStatusService.GetStatus(). Konkretna implementacja będzie zależna od tego jaką bazę danych testujemy i sposobu w jaki nawiązujemy z nią połączenie.
namespace healthchecks.Infrastructure.Persistence.Services;
public class DbStatusService(ILogger logger) : IDbStatusService
{
public async Task GetStatus(CancellationToken ct)
{
try
{
// TODO: Implement actual database health check logic
var result = new DbHealthStatus
{
Status = HealthStatus.Ready
};
// check your db system time zone and modify this accordingly to get UTC time
var timeZoneInfoResult = TimeZoneInfo
.TryFindSystemTimeZoneById("Eastern Standard Time", out var timeZoneInfo);
if (timeZoneInfoResult)
result.SystemTime = TimeZoneInfo
.ConvertTimeToUtc(result.SystemTime, timeZoneInfo!);
return result;
}
catch (Exception ex)
{
logger.LogError(ex, "Error getting database status");
throw;
}
}
}
W przykładzie w linii 12 zwracam HealthStatus.Ready, ale w rzeczywistości należałoby zmapować odpowiedź uzyskaną z bazy. Jeśli odpowiedzi z bazy w ogóle nie będzie, to już jest obsłużone w bloku catch DatabaseHealthCheck.CheckHealthAsync().
Procedura składowana
Oto procedura składowana. To przykład dla bazy Oracle.Tu widać, że wynik procedury powinien być mapowany na DbHealthStatus W procedurze pobierany jest czas SYSTIMESTAMP, który można porównać z czasem aplikacji i obsłużyć ewentualne różnice (status Error przy różnicy > próg). Liczony jest czas wykonania procedury. W przykładzie 1ms jest uznana za czas normalny, a dłuższy czas przekłada się na Slow. Jest też proste działanie matematyczne. Generalnie chodzi o to, żeby procedura była lekka, ale testowała stan bazy.
CREATE OR REPLACE PROCEDURE READINESS_TEST (
p_max_response_time IN NUMBER := 1,
p_cursor OUT SYS_REFCURSOR
)
IS
v_start_time TIMESTAMP(6);
v_end_time TIMESTAMP(6);
v_current_time DATE;
v_systimestamp TIMESTAMP(6);
v_user_name VARCHAR2(30);
v_session_id VARCHAR2(20);
v_status VARCHAR2(20);
v_message VARCHAR2(100);
v_sys_time VARCHAR2(30);
v_response_ms NUMBER;
v_math_result NUMBER;
v_max_time NUMBER;
BEGIN
v_start_time := SYSTIMESTAMP;
v_systimestamp := SYSTIMESTAMP;
v_status := 'INIT';
v_message := 'Starting';
v_response_ms := 0;
v_max_time := NVL(p_max_response_time, 1);
BEGIN
SELECT SYSDATE INTO v_current_time FROM DUAL;
SELECT SUBSTR(USER, 1, 20) INTO v_user_name FROM DUAL;
SELECT SUBSTR(TO_CHAR(SYS_CONTEXT('USERENV', 'SESSIONID')), 1, 15) INTO v_session_id FROM DUAL;
SELECT POWER(2, 3) INTO v_math_result FROM DUAL;
v_end_time := SYSTIMESTAMP;
v_response_ms := EXTRACT(DAY FROM (v_end_time - v_start_time)) * 86400000 +
EXTRACT(HOUR FROM (v_end_time - v_start_time)) * 3600000 +
EXTRACT(MINUTE FROM (v_end_time - v_start_time)) * 60000 +
EXTRACT(SECOND FROM (v_end_time - v_start_time)) * 1000;
v_sys_time := TO_CHAR(v_systimestamp, 'YYYY-MM-DD HH24:MI:SS');
IF v_response_ms <= v_max_time THEN
v_status := 'READY';
v_message := 'OK';
ELSE
v_status := 'SLOW';
v_message := 'TIMEOUT';
END IF;
EXCEPTION
WHEN OTHERS THEN
v_status := 'ERROR';
v_message := 'FAILED';
v_response_ms := -1;
v_sys_time := TO_CHAR(SYSTIMESTAMP, 'YYYY-MM-DD HH24:MI:SS');
END;
OPEN p_cursor FOR
SELECT v_status as Status,
v_response_ms as ResponseTime,
v_message as Message,
v_sys_time as SystemTime,
v_user_name as UserName,
v_session_id as SessionId
FROM DUAL;
EXCEPTION
WHEN OTHERS THEN
OPEN p_cursor FOR
SELECT 'CRITICAL' as Status,
-1 as ResponseTime,
'CRITICAL' as Message,
TO_CHAR(SYSTIMESTAMP, 'YYYY-MM-DD HH24:MI:SS') as SystemTime,
'UNKNOWN' as UserName,
'UNKNOWN' as SessionId
FROM DUAL;
END READINESS_TEST;
Rejestracja w kontenerze DI
Rejestracja to kolejny punkt przepisu. Do IServiceCollection dodaję serwis bazodanowy i implementację DatabaseHealthCheck. Zwróć uwagęj, że liveness probe jest zdefiniowana jedną linijką nr 9. Jeśli aplikacja „żyje” to na żądanie GET: /health/live zwróci 200-OK, a jeśli nie, to wystąpi timeout.
namespace healthchecks.Infrastructure.HealthChecks.Extensions;
public static class ServiceCollectionExtensions
{
public static IServiceCollection AddAppHealthChecks(this IServiceCollection services)
{
services.AddHealthChecks()
.AddCheck("database", tags: ["ready"])
.AddCheck("live", () => HealthCheckResult.Healthy("application"));
services.AddScoped();
return services;
}
}
Konfiguracja aplikacji
To ostatni punkt przepisu. Wykorzystujemy metody rozszerzające zdefiniowane wcześniej, Usuwamy zawartość Program.cs i wklejamy
var builder = WebApplication.CreateBuilder(args);
// health check services registration
builder.Services.AddAppHealthChecks();
var app = builder.Build();
// endpoint's mapping
WebApplicationExtensions.MapAppHealthChecks(app);
await app.RunAsync();
W launchsettings.json ustaw port dla żądań http na 5000. Ten sam podaj IT, żeby mogli skonfigurować testy po swojej stronie.
W linii 8 listingu AddAppHealthChecks rejestrowany jest DatabaseHealthCheck o tagu „ready”. Wcześniej napisałem, że readiness probe powinna sprawdzić wszystkie istotne składniki, żeby uznać aplikację za gotową do pracy. I że robimy to przez rejestrację kolejnych checków z tagiem „ready”, np. KafkaHealthCheck:
.AddCheck("messaging", tags: ["ready"])
Co się stanie, jeśli testy zwrócą różne wyniki? Odpowiedź jest krótka: zwyciąża najgorszy. Framework oblicza wynik ostateczny w następujący sposób:
Healthy < Degraded < Unhealthy
I jest to zgodne z tym czego się spodziewamy bo testach.
Test działania
Uruchom aplikację i wstaw do przeglądarki żądanie:
http://localhost:5000/health/ready
W odpowiedzi dostaniesz napis Healthy. W postmanie zobaczysz jeszcze status 200 OK.
Podsumowanie
Artykuł naświetlił tematykę testowania stanu aplikacji. W taki sam sposób możesz badać stan monolitów i mikroserwisów.
Była też okazja do prześledzenia implementacji health check i zbudowania działającej aplikacji demonstracyjnej. Wszyskto zostało objaśnienione. Wiesz też, jak dodawać kolejne testy. Mam nadzieję, że się przyda 🙂
Dziś coś z gatunku „Adam Słodowy”. Zrobimy sterowanie lampkami choinkowymi tak, żeby zapalały się o zmierzchu i gasły w nocy, kiedy pójdziemy spać i nie będziemy ich podziwiać. W dzień nie będą świeciły, co pomoże ocalić planetę i podniesie respect factor.
Do wykonania zadania Adam Słodowy wziąłby deseczkę, kilka gwoździ i młotek. Nasze zadanie także będzie wymagać paru fizycznych detali i zdolności majsterkowania. Tym razem sam kod nie wystarczy. Będziemy potrzebowali: Raspberry Pi, kilku przewodów. Konieczny też będzie przekaźnik, konwerter napięcia i lampki choinkowe. Przyda się też choinka, ale to dopiero na końcu. Zamiast młotka weź lutownicę. Tymczasem zakładam, że jeśli masz malinę, to pozostałe gadżety też znajdziesz w szufladzie.
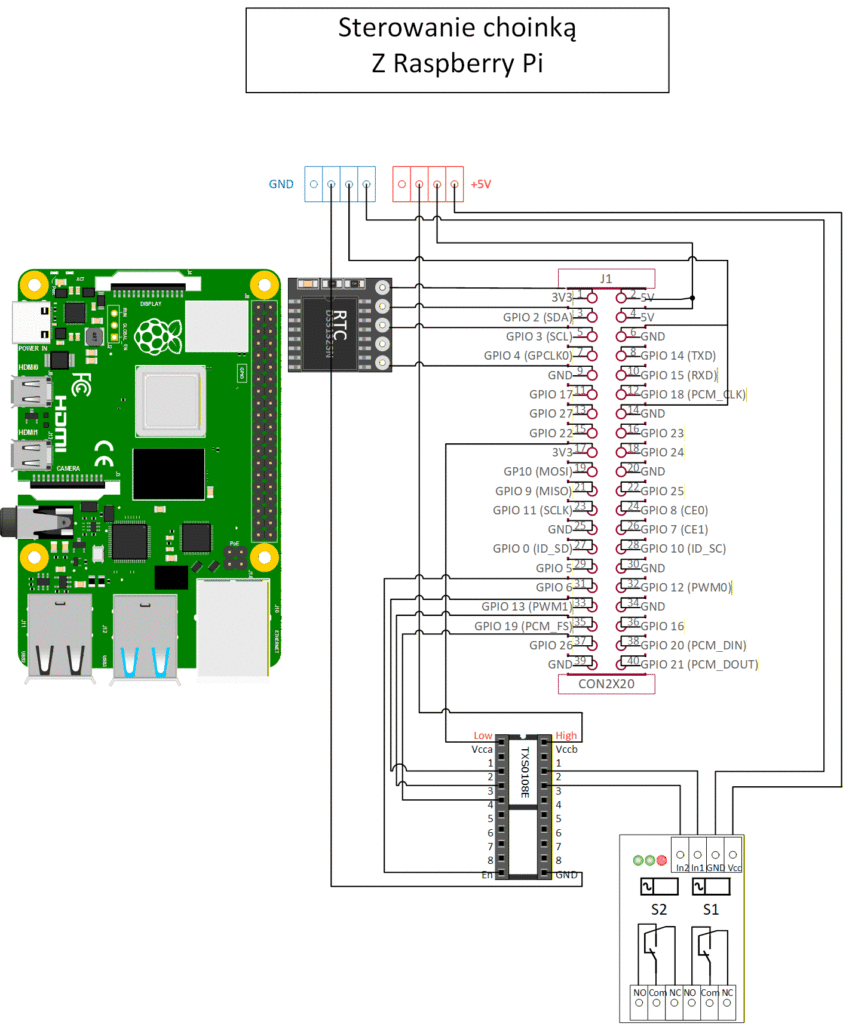
Elementy łączymy jak na schemacie. Zegar czasu rzeczywistego pokazany na schemacie to element opcjonalny i nie będę tu opisywał, jak go skonfigurować z maliną. Opisów jest dużo a procedura prosta. Raspbian wspiera RTC „z pudełka”. Zegar odpowiada za to, żeby malina nie zgubiła czasu, jeśli w mejscu instalacji nie ma dostępu do sieci.
Konwerter napięcia zapewni współpracę maliny (wejścia/wyjścia pracują z napięciem 3,3V, a element wykonawczy – przekaźnik jest zasilany napięciem 5V. Teoretycznie stan wysoki wyjścia maliny 3,3V powinien być powyżej progu stanu wysokiego takiego modułu (pewnie ok. 2,4V) ale jeśli chcemy mieć pewność, że to zadziała, to konwerter nie zaszkodzi. Jest jeszcze jeden powód stosowanie konwertera. W przypadku przypadkowego podania na wejście napięcia 5V nawet na chwilę, mamy prawie na pewno usmażony obwód wejściowy takiego wejścia. Nie wnikając teraz w elektronikę, powiem tylko, że mocno zalecam stosowanie konwertera.
Podłączenie obciążenia do modułu przekaźnikowego nie nastręczy Ci trudności, ani nie wymaga uprawnień SEP, ale zalecam ostrożność i stosowanie zasad bezpieczeństwa, jak przy każdej pracy z napięciem sieciowym.
Software
Program w C# będzie sterowany zdarzeniami. Składa się z podstawowego modułu zrealizowanego jako BackgroundService, który nasłuchuje, czy wystąpiło zdarzenie które ma włączyć lub wyłączyć przekaźnik. Skoro coś nasłuchuje, to należy także utworzyć moduły generujące zdarzenia. Potrzebne będą dwa zdarzenia: nadchodzi zmierzch (włącz lampki) oraz idę spać o 23.00 (wyłącz). Oba moduły generujące zdarzenia także będą BackgroundService’ami. Konieczny też będzie moduł sterujący fizycznymi wyjściami maliny. Wszystkie elementy omówimy po kolei. Na koniec zostanie wygenerowany kod dla maliny z gotowej aplikacji utrorzymy serwis systemowy.
Na początek utwórz projekt konsolowy i dodaj pakiety nuget potrzebne do zbudowania hosta. Dodamy też logger. Po wykonaniu pierwszego polecenia zmień folder na /choinka i wykonaj kolejne polecenia.
Następnie utwórz host, który za chwilę będziemy wypełniać treścią
using choinka.Triggers.SolarTime;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Serilog;
try
{
var hostBuilder= Host.CreateDefaultBuilder();
hostBuilder.Build().Run();
}
catch (Exception ex)
{
Log.Fatal("Fatar error: {Message}", ex.Message);
}
finally
{
Log.Information("Shutdown complete");
Log.CloseAndFlush();
}
Zegar astronomiczny
Lampki będziemy zapalać o zachodzie słońca. Nie ma sensu ustalać sztywnej godziny, bo w zimie moment zapadania ciemności zmienia się bardzo dynamicznie. Na przyklad. już w 10 dni po przesileniu, słońce zachodzi ok. 30 minut później. Słowem, nie ma co się męczyć i nieustannie przetawiać czas włączenia lampek, Niech się dzieje samo! Wykorzystamy bibliotekę SolarCalculator.
dotnet add package SolarCalculator
Niech godzina zachodu odpowiada lokalizacji geograficznej. Solar Calculator obliczy zachód słońca w oparciu o podany czas i lokalizację (koordynaty geograficzne). Dodajmy miejca. Dla mnie wystarczą Gdańsk i Warszawa. Ty dodaj swoje:
public class Places
{
public IEnumerable Coordinates { get; init; } = [
new Coordinates()
{
Name = "Warsaw", Latitude = 52.2298, Longitude = 21.0117
},
new Coordinates()
{
Name = "Gdansk", Latitude = 54.35, Longitude = 18.6667
},
];
}
public class Coordinates
{
public string Name { get; init; } = null!;
public Angle Latitude { get; init; } = Angle.Empty;
public Angle Longitude { get; init; } = Angle.Empty;
}
Potem dodamy Places do kontenera DI, bo za chwilę wstrzykniem je do serwisu. Ta akurat choinka będzie w Warszawie. Wobec tego pobieram koordynaty Warszawy w konstruktorze. Ty pobierz swoje koordynaty, które wcześniej zdefiniowałeś. Kalkulator może policzyć czasy wystąpienie bardzo różnych zjawisk astronomicznych. Ja potrzebuję czas zachodu słońca.
internal class SolarCalculator : ISolarCalculator
{
private readonly Coordinates _warsaw;
private readonly Places _places;
public SolarCalculator(Places places)
{
_places = places;
_warsaw = _places.Coordinates.First(c => c.Name.Equals(
"Warsaw", StringComparison.Ordinal));
}
public DateTime GetWarsawSunset(DateTimeOffset? date = null)
{
var time = new SolarTimes(date ?? DateTimeOffset.Now, _warsaw.Latitude, _warsaw.Longitude);
return time.Sunset;
}
}
internal interface ISolarCalculator
{
DateTime GetWarsawSunset(DateTimeOffset? date = null);
}
Teraz przychodzi czas na nieco ciekawszy kawałek kodu. Będzie to BackgroundService sprawdzający każdego dnia czy nadszedł zachód słońca. W odpowiednim momencie wywoła on event, którego obsługa będzie polegała na włączeniu lampek. Ten kawałek kodu objaśnię nieco szerzej już niedługo.
Solar Service
Zawiera dwa istotne elementy: Jeden to `event EventHandler SunsetOccurred` czyli zdarzenie, na które aplikacja zareaguje włączając lampki. Drugi element to logika obliczająca czas zachodu słońca i śledząca czy ten czas już nadszedł. Jest ona zaszyta w metodzie ExecuteAsync serwisu działającego w tle BackgroundService. ExecuteAsync uruchamia Task, który na początek bada, czy aplikacja nie została uruchomiona już po zachodzie słońca. W takim przypadku wywołuje zdarzenie SunsetOccurred. Po sprawdzeniu przechodzi do nieskończonej pętli (linia 52), w której, podobnie jak wcześniej, oblicza moment zachodu (ale już kolejnego dnia), oblicza też ile czasu zostało do tego zachodu, po czym przechodzi w uśpienie (linia 63). Kiedy czas minie event jest wywoływany pod warunkiem, że proces nie jest zamykany (linia 46). Dokładnie to CancellationToken przekazywany do metody ExecuteAsync wchodzi w stan canceled, kiedy wywołana jest metoda StopAsyncBackgroundService’u. A StopAsync jest wołana, kiedy host otrzyma wezwanie do zatrzymania od systemu operacyjnego. Na jedno wychodzi, ale warto być dokładnym 😉
Zwróć uwagę na to, że pobranie czasu nie jest zakodowane w tasku RunEventLoopAsync, funkcja obliczająca jest parametrem wywołania (linia 16). W ten sposób łatwiej wprowadzać zmiany, albo dodawać kolejne taski eventLoop (np. SunriseOccurred). Będą one miały analogiczną strukturę. Należy tylko w wywołaniu podać inny delegat Func<> i string reason. Zwróć też uwagę, że każdy handler jest wywoływany w oddzielnym bloku try/catch (linia 128). To chroni aplikację przed błędami, jakie mogłyby wystąpić w metodzie obsługi zdarzenia (handlerze). Normalnie, po błędzie, kolejne handlery zasubskrybowane do zdarzenia nie byłyby wywołane. Warto zapamiętać ten wzorzec.
Kod obsługuje wyjątki OperationCanceledException, które będą rzucane przy zamykaniu aplikacji. Osobiście uważam, że ten wyjątek zawsze powinien być obsłużony i kiedy zamykamy aplikację, to nie powinny temu towarzyszyć wyjątki w logach. Mała rzecz, a cieszy 🙂
internal class SolarNotifierService(
ILogger logger,
IServiceScopeFactory scopeFactory) : BackgroundService
{
public event EventHandler SunsetOccurred;
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
await RunEventLoopAsync(
"Zachód słońca",
(calc, date) => calc.GetWarsawSunset(date),
reason => InvokeSunsetEvent(reason),
stoppingToken);
}
private async Task RunEventLoopAsync(
string eventName,
Func getEventTime,
Action invokeEvent,
CancellationToken token)
{
try
{
// Initial check + possible catch-up
using (var scope = scopeFactory.CreateScope())
{
var calculator = scope.ServiceProvider.GetRequiredService();
var todayTime = getEventTime(calculator, null);
var now = DateTimeOffset.Now;
if (now > todayTime)
{
logger.LogWarning("Aplikacja uruchomiona po {EventName}. Wywołuję event natychmiast (catch-up).", eventName);
invokeEvent($"Zaległy {eventName} (start aplikacji po czasie)");
}
else
{
logger.LogInformation("Czekam na dzisiejszy {EventName}: {EventTime}", eventName, todayTime);
await WaitUntil(todayTime, token);
if (!token.IsCancellationRequested)
invokeEvent($"Dzisiejszy {eventName}");
}
}
// Daily loop
while (!token.IsCancellationRequested)
{
try
{
var tomorrow = DateTimeOffset.Now.AddDays(1);
using var scope = scopeFactory.CreateScope();
var calculator = scope.ServiceProvider.GetRequiredService();
var nextTime = getEventTime(calculator, tomorrow);
logger.LogInformation("Następny {EventName} zaplanowany na: {EventTime}", eventName, nextTime);
await WaitUntil(nextTime, token);
if (!token.IsCancellationRequested)
invokeEvent($"Planowy {eventName}");
}
catch (OperationCanceledException)
{
// cancellation requested - exit loop
break;
}
catch (Exception ex)
{
logger.LogError(ex, "Unexpected error in {EventName} loop", eventName);
try
{
await Task.Delay(TimeSpan.FromSeconds(5), token);
}
catch (OperationCanceledException)
{
break;
}
}
}
}
catch (OperationCanceledException)
{
// cancelled before starting - ignore
}
catch (Exception ex)
{
logger.LogError(ex, "Fatal error while starting {EventName} loop", eventName);
}
}
private async Task WaitUntil(DateTime targetTime, CancellationToken token)
{
var delay = targetTime - DateTime.Now;
if (delay.TotalMilliseconds > 0)
{
try
{
await Task.Delay(delay, token);
}
catch (TaskCanceledException)
{
logger.LogWarning("Task cancelled");
// ignore
}
}
}
private void InvokeSunsetEvent(string reason)
{
logger.LogInformation("EVENT: ZACHÓD SŁOŃCA ({reason})", reason);
SafeInvoke(SunsetOccurred, EventArgs.Empty, "SunsetOccurred");
}
private void SafeInvoke(EventHandler? handler, EventArgs args, string eventName)
{
if (handler == null)
return;
var invocationList = handler.GetInvocationList();
foreach (var @delegate in invocationList)
{
try
{
if (@delegate is EventHandler eventHandler)
eventHandler(this, args);
}
catch (Exception ex)
{
logger.LogError(ex, "Exception thrown by handler for {EventName}; continuing with other handlers", eventName);
}
}
}
}
Wschód słońca
Wspomniałem. że SolarNotifierService może obsługiwać więcej zdarzeń. Gdybyśmy chcieli coś zrobić np. o świcie, to wystarczy zdefiniować kolejne zdarzenie i uruchomić task realizujący logikę jego wywoływania. Zamiast linii 10-18 mielibyśmy coś takiego:
Oczywiście należałoby dodać definicję sunriseTask w sposób, który opisałem wcześniej. Trzeba też rozszerzyć interfejs ISolarCalculator o medodę GetWarsawSunrise i ją zaimplementować. Mając jednak wzorzec, to już pestka.
Alarm Clock Service
Żeby wyłączyć lampki potrzebujemy zdarzenia, że nadeszła 23:00. To jest zrealizowane analogicznie, jak w usłudze obsługującej zachód słońca. BackgroundService zawiera publiczny event EventHandler? Alarm2300Triggered, do którego za chwilę zasubskrybujemy procedurę wyłączenia prądu. Serwis zawiera także taskalarm2300Task uruchamiany przy jego starcie. Po szczegóły odsyłam do kodu na Githubie.
GpioController
Teraz wypadało by obsłużyć zdarzenia i spowodować zapalanie lampek, Normalnie użylibyśmy bezpośrednio sterownika GpioController pochodzącego z pakietu System.Device.Gpio. Ma on jednak pewną cechę, którą chcę zmodyfikować. Otóż twórcy biblioteki zakładają, że aplikacja może uruchomić GpioController, ustawić jakiś stan i zakończyć pracę. Przy czym konfiguracja i stan wyjścia pozostaje taki jaki został ustawiony. Nie jest przywracany stan „spoczynkowy”. Jest to pożądane przy np. zadaniach uruchamianych wg harmonogramu. Manipuluje się wtedy stanem wyjść i kończy pracę. Jednak w tym przypadku chcę, aby to działało inaczej. Chodzi o to, by kończąc pracę, aplikacja zmieniła stan na zdefiniowany jako „spoczynkowy*. Ma to zapobiec sytuacji, polegającej na tym, że jeśli między zachodzem słońca a 23:00 aplikacja lub system operacyjny zostaną zamknięte, to lampki pozostaną zapalone po 23:00.
Stan wyjścia GPIO
Muszę zdefiniować i utrzymać stan wyjścia w aplikacji. Będzie on trzymany w klasie PinState.
public class PinState(GpioPin pin, PinValue onClose, PinValue? value)
{
public static PinState CreateState(GpioPin pin, PinValue onCloseValue, PinValue? value) =>
new(pin, onCloseValue, value);
public GpioPin Pin { get; set; } = pin;
public PinValue OnCloseValue { get; set; } = onClose;
public PinValue? Value { get; set; } = value;
}
GpioControllerWithPinRestore
Stan będzie ustawiany w kontrolerze GpioControllerWithPinRestore, który wyłączy prąd i zdeaktywuje konwerter napięcia przy zamykaniu aplikacji. W tym celu rozszerzam GpioController.
Konstruktor jest „DI friendly” i przyjmuje wstrzyknięty Ilogger. Ten konstruktor zostanie wybrany przez kontener DI przy instancjonowaniu obiektu. .NET zawsze wybiera konstruktor (o ile ma wybór) który pozwoli na wstrztyknięcie jak największej liczby zarejestrowanych serwisów. Oprócz tego jest konstruktor bezparametrowy, który się przyda w aplikacji bez kontenera DI.
Przed użyciem wyjścia, trzeba wywołać OpenPin() (linia 14) i podać stan wyjcia, jaki chcemy mieć po zamknięciu aplikacji (onCloseValue). Jeśli tego nie zrobisz, to próba wykonania Write() (linia 21) rzuci wyjątek z bazowego GpioController.
Kontener DI przy zamykaniu aplikacji woła Dispose() (linia 34) dla wszystkich serwisów, które implenetują IDisposable. W tym momencie wyjścia zostaną ustawione w stan onCloseValue. Lampki zgasną. Sporo roboty, żeby zgasić światło 😉
public class GpioControllerWithPinRestore : GpioController, IDisposable
{
private readonly ConcurrentDictionary _pins = [];
private readonly ILogger? _logger;
public GpioControllerWithPinRestore(ILogger logger) : base()
{
_logger = logger;
}
public GpioControllerWithPinRestore() : base()
{ }
public GpioPin OpenPin(int pinNumber, PinMode mode, PinValue initialValue, PinValue onCloseValue)
{
var pin = base.OpenPin(pinNumber, mode, initialValue);
_pins.TryAdd(pinNumber, PinState.CreateState(pin, onCloseValue, initialValue));
return pin;
}
public new void Write(int pinNumber, PinValue value)
{
var isPinExisting = _pins.TryGetValue(pinNumber, out var pinState);
if (isPinExisting)
{
pinState!.Value = value;
_pins[pinNumber] = pinState;
}
base.Write(pinNumber, value);
}
// other commands omitted for brevity
public new void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this);
}
public new void Dispose(bool disposing)
{
foreach (var pin in _pins)
{
try
{
Write(pin.Key, pin.Value.OnCloseValue);
}
catch (Exception)
{
// ignore
}
}
base.Dispose(disposing);
}
}
Prawie wszystkie składowe są gotowe. Czas na ostatni, który je powiąże w funkcjonalną całość.
Główny serwis GpioWorker
Bardzo ważny, ale najprostszy z dotychczasowych serwis robi niewiele. Jego zadaniem jest zasubskrybowanie handlerów (tak, to te obrzydliwe metody void lub nawet gorzej async void) do zdarzeń. Na tym mógłby zakończyć pracę. Musi jednak być utrzymany przy życiu po to, żeby odśmiecacz Garbage collector nie usunął instancji a wraz z nią event handlerów trzymających referencje do metod obsługi.
Dobra praktyka nakazuje usunąć z listy subskrybcyjnej nieużywane handlery. To się dzieje w metodzie StopAsync() wołanej przez host przy jego zamykaniu.
internal class GpioWorker(
ILogger logger,
GpioControllerWithPinRestore gpioController,
SolarNotifierService solarNotifier,
AlarmClockService alarmClockService) : BackgroundService
{
const int _pinChoinka= 26;
const int _pinLevelConverter= 6;
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
try
{
// subscribe to notifications and ensure level converter is enabled
solarNotifier.SunsetOccurred += Choinka_OnEventOccurred;
alarmClockService.Alarm2300Triggered += Choinka_OffEventOccurred;
gpioController.OpenPin(_pinLevelConverter, PinMode.Output, PinValue.High, PinValue.Low);
if (gpioController.Read(_pinLevelConverter) == PinValue.Low)
gpioController.Write(_pinLevelConverter, PinValue.High);
await Task.Delay(Timeout.Infinite, stoppingToken);
}
catch (OperationCanceledException)
{
logger.LogInformation("GpioWorker cancellation requested");
}
catch (Exception ex)
{
logger.LogError(ex, "Error initializing GpioWorker. In case of error 13, try to elevate privileges and run the application with 'sudo'.");
}
}
public override Task StopAsync(CancellationToken cancellationToken)
{
logger.LogInformation("GpioWorker stopping, unsubscribing events and cleaning up pins");
try
{
solarNotifier.SunsetOccurred -= Choinka_OnEventOccurred;
alarmClockService.Alarm2300Triggered -= Choinka_OffEventOccurred;
}
catch (Exception ex)
{
logger.LogWarning(ex, "Error while stopping GpioWorker");
}
return base.StopAsync(cancellationToken);
}
private void Choinka_OnEventOccurred(object? sender, EventArgs e)
{
if(!gpioController.IsPinOpen(_pinLevelConverter))
gpioController.OpenPin(_pinLevelConverter, PinMode.Output, PinValue.High, PinValue.Low);
if (gpioController.Read(_pinLevelConverter) == PinValue.Low)
gpioController.Write(_pinLevelConverter, PinValue.High);
if (!gpioController.IsPinOpen(_pinChoinka))
gpioController.OpenPin(_pinChoinka, PinMode.Output, PinValue.Low, PinValue.Low);
if (gpioController.Read(_pinChoinka) == PinValue.Low)
gpioController.Write(_pinChoinka, PinValue.High);
}
private void Choinka_OffEventOccurred(object? sender, EventArgs e)
{
if (!gpioController.IsPinOpen(_pinChoinka))
gpioController.OpenPin(_pinChoinka, PinMode.Output, PinValue.Low, PinValue.Low);
else
gpioController.Write(_pinChoinka, PinValue.Low);
logger.LogInformation("Stan wyjścia: {StanChoinka}", gpioController.Read(_pinChoinka));
}
}
Rejestracja usług
W Program.cs przed linią 9 (z pierwszego listingu) dodajemy sekcję rejestrującą serwisy. To, co tu może zwróić uwagę, to sposób rejestracji usług tła BackgroundService. Nie rejestruję ich najpopularniejszym sposobem AddHostedService(), tylko rejestuję singleton (którym i tak są), ale używam przeciążenia biorącego funkcię AddHostedService(Func func). Tak mam zarejestowany singleton, który mogę wstrzyknąć do GpioWorker, i jednocześnie uruchamiam serwis w tle. To jest jeden z alternatywnych sposobów rejestracji. Przy okazji przestrzegam przed pomysłem typu AddHostedService(sp => new AlarmClockService()). To może i zadziała pozornie (po dodaniu konstruktora bezparametrowego, ale kontener DI nie będzie zarządzał cyklem życia takiego obiektu i może to mieć nie przewidziane konsekwencje.
hostBuilder.ConfigureServices((ctx, services) =>
{
services.AddSingleton(sp => new Places());
// sun time services
services.AddSingleton(sp => new Places());
services.AddScoped();
services.AddSingleton();
services.AddHostedService(sp => sp.GetRequiredService());
// timed event service
services.AddSingleton();
services.AddHostedService(sp => sp.GetRequiredService());
services.AddSingleton();
services.AddHostedService();
});
Wsparcie menedżera systemu i usług w Linuxie
Raspian (system operacyjny RaspberryPi) pochodzi od Ubuntu i jest systemem linuxowym. Wygodnie będzie wdrożyć lampki jako usuługę systemową. To daje wygodę polegającą m.in na tym, że usługa sama wstaje razem z systemem.
Na początek dodaj opcjonalny pakiet Systemd. Poprawia on współpracę z Menedżerem systemu i usług w systemie Linux.
I w Program.cs (po linii 8 pierwszego listingu) dodaj:
hostBuilder.UseSystemd();
Tu kończy się praca nad kodem C#. Pełna działająca wersja jest na moim Githubie
Publikacja projektu
Teraz trochę pracy DevOps. Jeśli chcesz zbudować projekt i uruchomić na malinie, to czytaj dalej. Jak już masz cały kod i buduje się on lokalnie, to czas wysłać go do maliny. Na początek opublikuj lokalnie aplikację ustawiając Linux jako docelowy OS. Zbudujemy aplikację, która nie będzia potrzebowała obecności .net na malinie (–self-contained true) i pakuje wszysko do jednego pliku (-p:PublishSingleFile=true). Rasbian ma już od dawna oficjalną wersję 64-bitową. Jeśli masz wersję 32-bitową, to wybierz odpowiednią komendę (przełącznik -r linux-arm64 lub -r linux-arm).
Prześlij kod na malinę i ustaw właściciela plików oraz uprawnienia do wykonywania poleceń (execute). Zmodyfikuj polecenia, aby odpowiadały nazwie użytkownika, jakiej używasz. W przykładzie użytkownikiem jest pi.
Już prawie koniec. Wystarczy przeładować demona menedżera i uruchomić usługę
sudo systemctl daemon-reload
sudo systemctl enable choinka.service
sudo systemctl start choinka.service
# tak możesz podejrzeć logi
sudo journalctl -u choinka.service -f
# a tak status usługi
sudo systemctl status choinka.service
To już definitywny koniec wpisu. Choinka świeci po zachodzie słońca a gaśnie o 23:00. Przy okazji pokazałem, jak działa aplikacja sterowana zdarzeniami i jak uruchomić usługę, króra przetwa restrart systemu w Linuxie. Miłego kodzenia 🙂
Czasem aplikacja ma reagować na zmiany zachodzące w systemie plików aby, np. przetwarzać nowe pliki, które właśnie ktoś do niego dodał. Nadaje się do tego świetnie klasa FileSystemWatcher (FSW). Działa w Windows i pod przy odpowiedniej konfiguracji także pod Linuxem. Ale słodycz się kończy po skonteneryzowaniu aplikacji. Trafił mi się właśnie taki przypadek. Kontener nie dostaje notyfikacji o zmianach w systemie plików woluminu zamontowanego do kontenera. Zupełna cisza, albo cytując klasyka „Ciemność, widzę ciemność!”
Przyczyną tego stanu rzeczy są różne mechanizmy generowania i transmisji zdarzeń o zmianie w systemie plików przez różne OS, systemy plików, protokoły sieciowe. FileSystemWatcher instancjonuje obiekt inotify dla każdego śledzonego folderu, który nasłuchuje na zdarzenia generowane przez system plików. Jeśli jednak nastąpi błąd sieci, to zdarzenie nie dotrze. Jeśli przepełni się bufor zdarzeń, to zdarzenie nie dotrze, Jeśli system plików nie potrafi w sposób powtarzalny wysłać powiadomień, to one nie będą docierały. Tych jeżeli… jest sporo i zawsze kończą się tym, że zdarzenie nie dotrze. FSW sprawdza się w zasadzie jedynie dla dysków lokalnych i to najlepiej pod Windows.
A tymczasem w folderze jest coraz więcej plików, a aplikacja nie reaguje. Co robić? Pooling udziału sieciowego? Nic innego nie pozostaje.
Można do tego zastosować PhysicalFileProvider. W odróżnieniu od FSW, nie pozwala on na wybór rodzaju zdarzeń, które notyfikuje, ale powinien wystarczyć przynajmniej jako źródło informacji, że „coś się zmieniło”. Po prostu zostanie ustawiony cykliczny pooling folderu. Nie ma innego wyjścia w Dockerze. Sami będziemy musieli dowiedzieć się, jak zmiana zaszła. Jedynie co wiadomo, to że zaszła. Ale dobre i to.
Za to wykonamy porządną implementację obsługi kolejki zdarzeń. Przecież może się zdarzyć, że zdarzenia o nowych plikach będą spływały szybciej niż trwa ich obsługa. Wykorzystamy generyczną BlockingCollection do jednoczesnego dodawania i konsumowania zdarzeń. To kolejka FIFO, która jest bezpieczna dla wielu wątków (thread-safe). Jeden wątek może dodawać zdarzenia informujące o nowych plikach, a inny obsługiwać te zdarzenia. Nasz DirectoryWatcher ma następujący interfejs:
Po zainstancjonowaniu DirectoryWatchera rejestruje się callback. Jest on wołany w momencie obsługi zdarzenia pobieranego z kolejki. W przykładzie callbackiem jest medoda synchroniczna. Jest ona wołana w osobnym wątku, tym samym który obsługuje kolejkę. Obsługa callbacka nie nie blokuje działania pozostałego kodu. W razie potrzeby można łatwo zmienić kod, aby wywołanie było asynchroniczne.
Potem wystarczy uruchomić DirectoryWatcher wywołując StartWatching. Metoda wygląda tak:
public async Task StartWatching(CancellationToken ct = default)
{
_fileSystemEventBuffer = new BlockingCollection(EventBufferSize);
CreateFileWatcher();
_fileWatcherCallback = WatchForFileChanges();
var processBuffer = Task.Run(() =>
{
foreach (var fileInfo in _fileSystemEventBuffer.GetConsumingEnumerable(ct))
{
_callback?.Invoke(fileInfo.PhysicalPath!);
LogWhenBufferIsEmpty();
}
}, ct);
// Implement resilience to transient IO errors
_files = GetFiles();
BufferFiles();
await processBuffer.ConfigureAwait(false);
}
Deklaracje zmiennych i stałych na razie pominę. Zostaną pokazane w dalszej części. Podobnie metody CreateFileWatcher() i WatchForFileChanges(). Teraz opiszę działanie typu BlockingCollection. Tworzymy bufor new BlockingCollection(EventBufferSize). W linii 8 uruchamiany jest wątek, który pobiera z kolejki informacje o nowych plikach i wywołuje callback. Kluczowe tu jest, że pętla się „nie kończy”. Po skonsumowaniu wszyskich zdarzeń zostaje „uśpiona” i wznawia działanie kiedy do kolekcji wpadną nowe elementy. A mogą one być dodawane w każdym momencie w innym wątku. Możemy zatem spokojnie w swoim tempie obsługiwać zdarzenia nie martwiąc się o zablokowanie możliwości ich dodawania. W linii 18 pobieramy informacje o plikach, bo na starcie programu zakładamy, że wszystkie pliki są nowe. Definicja metody GetFiles():
private List GetFiles() => _fileWatcher!.GetDirectoryContents(string.Empty).ToList();
Następnie wszyskie dane wrzucamy do bufora (linia 19). Kiedy tylko zostanie dodany pierwszy rekord, wznawia pracę pętla foreach z linii 10 i wywoływany jest callback.
private void BufferFiles()
{
foreach (var fileInfo in _files!)
{
if (!_fileSystemEventBuffer!.TryAdd(fileInfo))
Console.WriteLine($"Buffer size exceeded ({EventBufferSize}) or buffer is disposed");
}
}
I do by było na tyle, jeśli idzie o mechanizm bufora. Wielowątkowo dodajemy do niego i konsumujemy obiekty. Dla reszty kodu działanie „głównej pętli” odbywa się „w tle” nie wpływając na pracę innych wątków. Nie jest to wątek tła, ale dzięki asynchroniczności i bezpiecznemu dla wątków api BlockingCollection możemy tak roboczo przyjąć.
Do omówienia został mechanizm notyfikacji o nowych plikach w folderze. Na początek metoda CreateFileWatcher() wołana w linii 5 metody StartWatching(). Instancjonujemy PhysicalFileProvider, który nie będzie brał pod uwagę plików ukrytych (także z kropką) ani systemowych. Będzie za to cyklicznie sięgał do folderu na okoliczność wykrycia zmian w systemie plików. Nic specjalnego.
W linii 7 wskazujemy jakie pliki nas interesują używając filtra. Metoda Watch() zwraca IChangeToken, który będzie notyfikowany o zmianach śledzonych plików. Następnie temu tokenowi wskazujemy callback jaki ma wywołać w wyniku notyfikacji (NotifyFileChange). W moich próbach po jednorazowej notyfikacji IChangeToken przestawał być użyteczny. Albo przestawał być notyfikowany o zmianach, albo rejestacja callbacka wygasała. W każdym razie w linii 15 ponownie wołam metodę WatchForFileChanges(), aby notyfikacje znów działały. A chcemy, żeby działały nieustannie nasłuchując na nowe pliki.
Teraz robi się ciekawiej. Trzeba jakoś ogarnąć różne stany w jakich może się znaleźć Watcher. Wyróżniłem trzy stany:
0 – nie trwa proces buforowania (dodawania zmian do kolekcji), brak notyfikacji o zmianach
1 – trwa proces buforowania, brak notyfikacji o zmianach,
2 – trwa proces buforowania i nadeszła notyfikacja o zmianach
Do przechowywania informacji, w jakim stanie jest Watcher, wykorzystałem zmienną statyczną, do której dostęp uzyskuję przez klasę Interlocked. Ta klasa zapewnia dostęp do zmiennej w sposób bezpieczny z różnych wątków (thread-safe).
W metodzie NotifyFileChange() jeśli mamy stan 0, to buforujemy nowe pliki i następuje zmiana stanu na 1. W przeciwnych przypadku ustawiamy stan na 2. Co się dzieje dalej, pokazują kolejne listingi.
private void BufferNewFiles()
{
do
{
Interlocked.CompareExchange(ref _changeLevel, 1, 2);
var filesActual = GetFiles();
var newFiles = filesActual.ExceptBy(_files!.Select(f => f.Name), fi => fi.Name);
_files = filesActual;
foreach (var fileInfo in newFiles)
{
if (!_fileSystemEventBuffer?.TryAdd(fileInfo) ?? false)
Console.WriteLine($"Buffer size exceeded ({EventBufferSize}) or buffer is disposed");
}
} while (1 < Interlocked.Read(ref _changeLevel));
Interlocked.Exchange(ref _changeLevel, 0);
}
Metoda BufferNewFiles() na początek zmienia stan na 1 „trwa proces buforowania”. Pobiera aktualną listę plików w folderze, porównuje z zachowaną w pamięci i nowe pliki dodaje do bufora. Zastosowałem proste porównanie nazw plików, co nie zawsze musi być jednoznaczne. Gdybyśmy chcieli wykrywać zmianę plików (a nie dodanie nowych), to można by liczyć hash zawartości i przechowywać go jako wartość w słowniku, a znormalizowaną nazwę (albo jej hash) jako klucz. Ale w tym wpisie skupiam się na funkcji bezpiecznego i skutecznego notyfikowania o zmianach w folderze na poziomie systemu plików.
Po dodaniu plików do bufora, sprawdzana jest aktualna wartość _changeLevel, Jeśli jest 2, czyli w trakcie aktualizacji bufora pojawiła się notyfikacja o zmianach, powtarzamy proces buforowania. Jeśli nie, to kończy się proces buforowania a stan przyjmuje wartość 0. Watcher oczekuje na notyfikację.
W praktyce zdarzają się sytuacje, że notyfikacja nie nadchodzi. Pisałem o tym na początku. Można przyjąć dwie strategie wobec takich przypaków. Albo czeka się na następną notyfikację, po której i tak badana jest zawartość folderu, więc nowy plik nie umknie. Ale jeżeli założenie biznesowe jest takie, że nowe pliki mogą się pojawiać w takich dużych odstępach, że nie można sobie pozwolić na oczekiwanie z przetworzeniem pominiętego pliku, to trzeba znaleźć inne rozwiązanie. Ja przyjąłem drugi scenariusz. Timer co jakiś czas sprawdza folder nawet jak notyfikacja nie nadejdzie. Natomiast robi to w dużych interwałach i jego praca jest wstrzymywana, jeśli pliki są buforowane (_changeLevel != 0). Timer jest widoczny poniżej na pełnym listu Watchera.
using System.Collections.Concurrent;
using Microsoft.Extensions.FileProviders;
using Microsoft.Extensions.FileProviders.Physical;
using Microsoft.Extensions.Primitives;
namespace DirectoryWatcher.DirectoryWatcher;
public class DirectoryWatcherWithPolling : IDirectoryWatcher, IDisposable
{
private const int EventBufferSize = 100000;
private const int DirectoryPollingInterval = 300;
private readonly string _directoryToWatch;
private static ulong _changeLevel;
private Action? _callback;
private IEnumerable? _files;
private BlockingCollection? _fileSystemEventBuffer;
private PhysicalFileProvider? _fileWatcher;
private IChangeToken? _changeToken;
private IDisposable? _fileWatcherCallback;
private PeriodicTimer? _timer;
public DirectoryWatcherWithPolling(string directoryToWatch)
{
if (string.IsNullOrEmpty(directoryToWatch) || !Directory.Exists(directoryToWatch))
throw new ArgumentException("Directory can not be empty string");
_directoryToWatch = directoryToWatch;
}
public void RegisterCallback(Action? callback) => _callback = callback;
public async Task StartWatching(Action? callback, CancellationToken ct = default)
{
RegisterCallback(callback);
await StartWatching(ct);
}
public async Task StartWatching(CancellationToken ct = default)
{
try
{
_timer = new PeriodicTimer(TimeSpan.FromSeconds(DirectoryPollingInterval));
_fileSystemEventBuffer = new BlockingCollection(EventBufferSize);
CreateFileWatcher();
_fileWatcherCallback = WatchForFileChanges();
var processBuffer = Task.Run(() =>
{
foreach (var fileInfo in _fileSystemEventBuffer.GetConsumingEnumerable(ct))
{
_callback?.Invoke(fileInfo.PhysicalPath!);
LogWhenBufferIsEmpty();
}
}, ct);
// TODO Implement resilience policy
_files = GetFiles();
BufferFiles();
while (await _timer.WaitForNextTickAsync(ct))
{
if (Interlocked.Read(ref _changeLevel) != 0) continue;
_fileWatcher?.Dispose();
Console.WriteLine("Directory polling upon timer");
BufferNewFiles();
CreateFileWatcher();
_fileWatcherCallback = WatchForFileChanges();
}
await processBuffer.ConfigureAwait(false);
}
catch (OperationCanceledException)
{
// ignore
}
finally
{
Dispose();
}
}
private void LogWhenBufferIsEmpty()
{
if (_fileSystemEventBuffer?.Count == 0)
Console.WriteLine("Synchronisation buffer is empty");
}
private List GetFiles() =>
_fileWatcher!.GetDirectoryContents(string.Empty).ToList();
private void CreateFileWatcher()
{
// TODO Implement resilience policy
_fileWatcher = new PhysicalFileProvider(_directoryToWatch, ExclusionFilters.Sensitive)
{
UsePollingFileWatcher = true,
UseActivePolling = true
};
}
private IDisposable WatchForFileChanges()
{
_changeToken = _fileWatcher!.Watch("**/*.*");
return _changeToken.RegisterChangeCallback(_ => NotifyFileChange(), default);
}
private void NotifyFileChange()
{
Console.WriteLine("Directory has changed. Callback invoked");
_fileWatcherCallback = WatchForFileChanges();
if (0 == Interlocked.CompareExchange(ref _changeLevel, 1, 0))
BufferNewFiles();
else
Interlocked.Exchange(ref _changeLevel, 2);
}
private void BufferFiles()
{
foreach (var fileInfo in _files!)
{
if (!_fileSystemEventBuffer!.TryAdd(fileInfo))
Console.WriteLine($"Buffer size exceeded ({EventBufferSize}) or buffer is disposed");
}
}
private void BufferNewFiles()
{
do
{
Interlocked.CompareExchange(ref _changeLevel, 1, 2);
// TODO Implement resilience policy
var filesActual = GetFiles();
var newFiles = filesActual.ExceptBy(_files!.Select(f => f.Name), fi => fi.Name);
_files = filesActual;
foreach (var fileInfo in newFiles)
{
if (!_fileSystemEventBuffer?.TryAdd(fileInfo) ?? false)
Console.WriteLine($"Buffer size exceeded ({EventBufferSize}) or buffer is disposed");
}
} while (1 < Interlocked.Read(ref _changeLevel));
Interlocked.Exchange(ref _changeLevel, 0);
}
private bool _isDisposed;
public void Dispose() => Dispose(true);
private void Dispose(bool disposing)
{
if (_isDisposed) return;
if (disposing)
{
_fileWatcherCallback?.Dispose();
_fileSystemEventBuffer?.Dispose();
_timer?.Dispose();
}
_isDisposed = true;
}
}
Uwagi na koniec. Skupiłem się na pokazaniu, jak sprawnie nasłuchiwać na zmiany w systemie plików przez aplikację działającą w kontenerze Dockera, gdzie nie zadziała FileSystemWatcher. Zaprezentowany mechanizm działa bardzo dobrze. W produkcji klasa DirectoryWatcherWithPolling jest instancjonowana z kontenera DI. Wstrzykiwany jest logger (zamiast wyjścia na konsolę), polityki odporności na błędy IO (każde odwołanie do dysku jest „uodpornione” na chwilowe błędy IO) i ustawienia.
Na Githubie można zapoznać się z przykładową aplikacją, wykorzystującą DirectoryWatcher.
Jak wspomniałem w poptrzednim wpisie na ten temat, zadanie polega na znalezieniu takich działań, które wstawione pomiędzy liczby dadzą równianie. Dla utrudnienia, poszczególne składniki obu części równości można łączyć tworząc liczbę składającą się z cyfr obu składowych. Nie można przestawiać kolejności składników ani cyfr w składnikach. Wynik każdego działania musi być liczbą całkowitą, a składowe muszą być liczbą całkowitą dodatnią. Dla przykładu dane składowe 1 i 23 można zestawić tak: 1 + 23 1 – 23 1 * 23 123 (1 / 23 odpada, bo wynik dzielenia pozostawia resztę)
Program będzie wykonywał sekwencję:
Przyjmie dane wejściowe
Wygeneruje możliwe kombinacje dla obu stron równiania
Policzy wartość każdego wyrażenia eliminując te, które nie spełniają wymagania dzielenia bez reszty
Znajdzie kombinacje obu stron równania, które można zestawić ze sobą (dają równość)
Wyświetli wyniki
W tym wpisie zajmę się utworzeniem wyrażeń dla jednej strony równania. W kolejnych wpisach, kiedy będą obliczane wartości wyrażeń (punkt 3), wywołamy kod dwuktotnie. Część 1 i 5 będą pokazane na końcu, kiedy zbudowana zostanie aplikacja Blazor a z nią interfejs użytkownika.
Na początek utworzymy obiekt – model wyrażenia. Będzie on zawierał listę składowych i listę działań matematycznych. Oprócz tego zapiszemy wynik wyrażenia oraz flagę wskazującą, czy działanie jest ważne czy też błędne. Zdefiniujmy też dozwolone działania matematyczne.
public class Expression
{
public List Numbers { get; set; } = new();
public List Operations { get; set; } = new();
public int? CalculatedResult { get; set; }
public bool ErrorOccured { get; set; }
}
public enum OperationType
{
Add,
Substract,
Multiplicate,
Divide
}
Właściwości Numbers i Operations są od razu inicjalizowane, bo za chwilę będą w nich przechowywane kolejne elementy. Dla wyrażenia '1+23′ instancja Expression będzie zawierała w liście Numbers kolejno liczby 1, 23 a Operations jedną z operacji.
Wykonajmy metodę budującą te wyrażenia. Znajdzie się ona w klasie ExpressionBuilder. Wyrażenia będą budowane od lewej. Wejściowa lista liczb, np. 1, 2, 3 będzie dzielona na liczby z lewej strony operacji oraz na te z prawej strony. Pomiędzy nie wstawiamy po kolei operacje Add, Substract, Multiplicate, Divide. Na początku pozycja podziału znajduje się pomiędzy 1 (leftHandNumbers linia 13) a 2 i 3 (rightHandNumbers linia 19). W linii 14 wywoływana jest funkcja GetPartialExpressions, do której przekazywane są leftHandNumbers i całe wyrażenie. Tam tworzone są operacje częściowe 1+, 1-, 1* i 1/. Funkcja zwraca wyliczenie takich częściowych operacji. Potem w linii 18-20 do każdej z operacji częściowych dodawana jest nowa liczba powstała z połączenia składników rightHandNumbers (dla naszego przykładu jest to 23), a całe wyrażenie (1+23, 1-23 1*23, 1/23) dodawane do listy gotowych wyrażeń (linia 21). Następnie rekurencyjnie wołamy metodę CreateExpressions dla każdego elementu partialExpression przekazując rightHandNumbers (liczby 2 i 3). Co się tam wydarzy? Do każdego wyrażenia częściowego zostaną dobudowane kolejne: 1+2+ 1+2- 1+2* 1+2/ 1-2+ 1-2- ….. i tak dalej. Potem znów zostanie wywołana rekurencyjnie CreateExpressions. I tak do momentu, aż zabraknie składowych po prawej stronie i nie da się przesunąć wskaźnika position w prawo. Przypadek z trzema składowymi jest jeszcze prosty, ale przy większej ich liczbie pojawiają się wyrażenia bardziej złożone, np. 123 + 4 – 56 / 7 * 6 – 89.
public class ExpressionBuilder
{
private List Expressions { get; } = new();
private void CreateExpressions(ICollection numbers, Expression? expression = null)
{
var position = 0;
while (position < numbers.Count - 1)
{
++position;
var leftHandNumbers = numbers.Take(position);
var partialExpressions = GetPartialExpressions(leftHandNumbers.ToNumber(), expression);
foreach (var partialExpression in partialExpressions)
{
var newExpression = partialExpression.Clone();
var rightHandNumbers = numbers.Skip(position).ToList();
newExpression.Numbers.Add(rightHandNumbers.ToNumber());
Expressions.Add(newExpression);
CreateExpressions(rightHandNumbers.ToArray(), partialExpression);
}
}
}
private static IEnumerable GetPartialExpressions(int number, Expression expression)
{
var newExpressions = new List();
foreach (var operation in Enum.GetValues())
{
var newExpression = expression.Clone();
newExpression.Numbers.Add(number);
newExpression.Operations.Add(operation);
newExpressions.Add(newExpression);
}
return newExpressions;
}
}
Za każdym razem, kiedy tworzymy nowe wyrażenie, robimy to na podstawie innego, nie do końca zbudowanego wyrażenia częściowego. To częściowe wyrażenie jest bazą dla budowy kilku nowych. Za każdym razem musi być utworzona kompletna kopia włączając kopiowanie typów referencyjnych składających się na wyrażenie (metoda Clone w liniach 18 i 33). Jest to tzw. deep copyWięcej od Microsoftu o kopiowaniu typów. Metoda jest składową typu Expression. Uzupełnijmy zatem listing
public class Expression
{
public List Numbers { get; set; } = new();
public List Operations { get; set; } = new();
public int? CalculatedResult { get; set; }
public bool ErrorOccured { get; set; }
public Expression Clone()
{
var clone = (Expression)MemberwiseClone();
clone.Numbers = new List(Numbers);
clone.Operations = new List(Operations);
return clone;
}
}
Ponadto używana jest medoda ToNumber rozszerzająca typ IEnumerable. To mała metoda pomocnicza do konkretnego zastosowania. Nie ma sensu tworzyć jej generycznego odpowiednika, choć byłoby to możliwe.
public static class Extensions
{
public static int ToNumber(this IEnumerable numbers)
{
return int.Parse(string.Concat(numbers));
}
}
Listing klasy ExpressionBuilder powyżej jest nieco uproszczony, aby nie zaciemniać podstawowego kodu tworzącego wyrażenie. Ale dla pełnego obrazu przytaczam całość z komentarzami w punktach:
Zdefiniowana jest tu metoda GetExpressions, która pozwala nasz obiekt poprosić o wyniki. Osobiśnie wolę takie podejście, niż wydawać polecenie expressionBuilder.CreateExpressions(), a potem odczytywać właściwość Expressions. Niech procedura wykonania zadania pozostanie wewnętrzną sprawą obiektu. My prosimy tylko o dostarczenie wyników.
Linia 13 rozwiązuje przypadek brzegowy, kiedy przekazywana kolekcja nie zawiera żadnej liczby.
Sprawdzamy, czy to jest pierwsza iteracja (linia 15) i wtedy dodajemy do wyników wyrażenie złożone z połączonych liczb nie zawierające żadnej operacji. Dodatkowo sprawdzany jest warunek brzegowy, czy przekazana kolekcja zawiera pojedynczą liczbę. Jeśli tak, to jest ona jedynym składniniej wyrażenia i metoda kończy pracę (linia 20).
Piersze wywołanie GetPartialExpressions (przy pierwszej iteracji) przekazuje nowy 'pusty’ obiekt Expression (linia 31).
public class ExpressionBuilder
{
private List Expressions { get; } = new();
public List GetExpressions(ICollection numbers)
{
CreateExpressions(numbers);
return Expressions;
}
private void CreateExpressions(ICollection numbers, Expression? expression = null)
{
if (!numbers.Any()) return;
if (expression is null)
{
var newExpression = new Expression();
newExpression.Numbers.Add(numbers.ToNumber());
Expressions.Add(newExpression);
if (numbers.Count == 1) return;
}
var position = 0;
while (position < numbers.Count - 1)
{
++position;
var leftHandNumbers = numbers.Take(position);
var partialExpressions = GetPartialExpressions(leftHandNumbers.ToNumber(),
expression ??= new Expression());
foreach (var partialExpression in partialExpressions)
{
var newExpression = partialExpression.Clone();
var rightHandNumbers = numbers.Skip(position).ToList();
newExpression.Numbers.Add(rightHandNumbers.ToNumber());
Expressions.Add(newExpression);
CreateExpressions(rightHandNumbers.ToArray(), partialExpression);
}
}
}
private static IEnumerable GetPartialExpressions(int number, Expression expression)
{
var newExpressions = new List();
foreach (var operation in Enum.GetValues())
{
var newExpression = expression.Clone();
newExpression.Numbers.Add(number);
newExpression.Operations.Add(operation);
newExpressions.Add(newExpression);
}
return newExpressions;
}
}
Na koniec uzupełniamy obiekt Expression naszą wersją metody ToString. Będzie potrzebna przy drukowaniu wyników, kiedy będziemy chcieli pokazać każde wyrażenie w postaci czytelnej dla człowieka.
public class Expression
{
// tu kod z poprzedniego listingu klasy Expression
public override string ToString()
{
if (!Operations.Any()) return Numbers.FirstOrDefault().ToString();
var sb = new StringBuilder();
var position = 0;
while (position < Operations.Count)
{
sb.Append(Numbers[position]);
switch (Operations[position])
{
case OperationType.Add:
sb.Append(" + ");
break;
case OperationType.Substract:
sb.Append(" - ");
break;
case OperationType.Multiplicate:
sb.Append(" * ");
break;
case OperationType.Divide:
sb.Append(" / ");
break;
}
++position;
}
sb.Append(Numbers.Last());
return sb.ToString();
}
}
To na razie tyle. W następnym wpisie zbudujemy kalkulator, który policzy nam wartość wyrażenia z zachowaniem kolejności działań.
Zainspirowany pewną zagadką, którą otrzymałem na interview napisałem aplikację, która pozwoli obniżyć poziom stresu przynajmniej do momentu, aż rekturerzy znajdą ten wpis i wymyślą inne zagadki 🙂 Zresztą spotkałem się w takim zadankiem już wcześniej, więc tym bardziej zachciałem sprawę ogarnąć. Otóż jest pewna kategoria zabaw matematycznych, która polega na tym, że z kilku cyfr zestawia się równanie, które jest „niedokończone”. Należy pogrupować cyfry i powstawiać między nie operatory +, -, *, / aby równanie było prawdziwe. Przykład:
4 4 4 4 4 = 5 5
Rozwiązania:
44 / 4 - 4 / 4 = 5 + 5
44 + 44 / 4 = 55
44 / 4 + 44 = 55
Albo takie cyferki:
1 2 3 4 = 5 6
Można powiązać następująco:
1 - 2 * 3 + 4 = 5 - 6
1 + 2 * 3 + 4 = 5 + 6
1 - 2 + 3 * 4 = 5 + 6
12 + 3 - 4 = 5 + 6
Nie umniejszając zaletom łamania głowy przy wynajdowaniu rozwiązań, ja postanowiłem do sprawy podejść programistycznie. Powstała aplikacja, która znajduje wszystkie możliwe rozwiązania dla danych zestawów liczb. Można się nią posłużyć przy rozstrzyganiu zakładów o to, ile jest możliwych rozwiązań, tworzeniu zagadek (to dla rekruterów), albo ich rozwiązywaniu (aplikanci). Programik jest dostępny tu Play With Numbers (uwaga: Azure Apps w bezpłatnej wersji potrafią 'zamrozić’ aplikację, a jest przywracanie trwa nawet 3-4 minuty). W kolejnych wpisach blogu poznany algorytm, który program napędza.
Duże jest na początku małe. Potem rośnie. Dotyczy to także oprogramowania. Zanim zrobię „dużą” bazę, to czasem mam potrzebę wykonania prototypu. Nie musi on odzwierciedlać wszystkich encji, ale te których powiązania chcę sprawdzić. Po co tak? W przypadku Entity Framework, warto popatrzeć, co wyprodukuje framework czy to z modeli i 'annotations’, czy z kodu fluent api. To nie jest to T-SQL, gdzie widzę, co piszę 😉 Dlatego szybki prototyp się przydaje. W tym celu robię sobie migrację i aplikuję ją do bazy. Wtedy widać jaka będzie finalna postać moich zamierzeń. Mogę ją też przetestować.
Nie przedłużając, bo to ma być szybki prototyp a pizza już jest w piekarniku, zabieramy się do pracy 😉
Robimy sobie folder na naszą aplikację, w której utworzymy modele encji. Zakładam, że .NET SDK i MSSQL Server mamy zainstalowane. Potrzebne też będzie narzędzie dotnet-ef. Kto ma, to pomija pierwsze polecenie.
Środowisko testowe mamy gotowe. Teraz przyszedł czas na obiekt, który będzie testowany. Otwieramy projekt w ulubionym IDE i dodajemy DbContext.
using Alamakota.Entities;
using Microsoft.EntityFrameworkCore;
namespace Alamakota;
public class ApplicationContext : DbContext
{
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer(@"Data Source=.\SQLEXPRESS;Initial Catalog=ala-test;Integrated Security=True;Trust Server Certificate=Yes");
}
}
To sprawdźmy, czy wszystko jest w porządku? Poniższa komenda powinna zbudować aplikację i zwrócić wynik: C:\Users\marek\Alamakota> dotnet ef migrations list Build started… Build succeeded. No migrations were found.
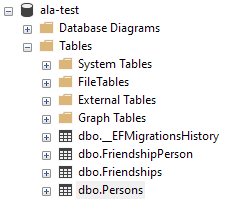
Fakt, nie mamy jeszcze migracji, ani bazy, ale wiemy, że aplikacja się buduje i mamy połączenie z serwerem. To czas na jakieś modele, np.
namespace Alamakota.Entities;
public class Person
{
public int Id { get; set; }
public string Name { get; set; } = null!;
public virtual ICollection? Friendships { get; set; }
}
public class Friendship
{
public int Id { get; set; }
public virtual ICollection? Persons { get; set; }
}
Uzupełniamy ApplicationContext dodając poniżej metody OnConfiguring obiekty DbSet<> i inicjalizujemy bazę danymi.
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity().HasData(new Person { Id = 1, Name = "Ala" });
modelBuilder.Entity().HasData(new Person { Id = 2, Name = "Bolek" });
modelBuilder.Entity().HasData(new Person { Id = 3, Name = "Lolek" });
}
public DbSet Persons { get; set; } = null!;
public DbSet Friendships { get; set; } = null!;
Następnie tworzymy pierwszą migrację oraz aplikujemy ją do bazy. C:\Users\marek\Alamakota> dotnet ef migrations add initial C:\Users\marek\Alamakota> dotnet ef database update Serwer powinien pokazać nową bazę i tabele.
I to by było w zasadzie wszystko, co istotne. Mamy bazę, której strukturę chcieliśmy sprawdzić. Dla mnie najważniejszy jest plik ApplicationContextModelSnapshot.cs który Entity Framework utworzył w folderze Migrations. W nim widzę, jak framework przełożył mój kod na polecenia fluent api, które są odzwierciedlane w bazie danych. Trzeba jednak pamiętać, że ten kod, nie pokazuje w 100% tego co się wydarzy w bazie. Framework posługuje się pewnymi ustawieniami domyślnymi. W kodzie fluent api nie wszystko jest uwidocznione. Np. domyślnie na kluczu głównym zakładany jest indeks klastrowy, a w kodzie tego nie widać. Zawsze jednak można sobie z poziomu MSSMS wygenerować skrypt odtwarzający interesujący element, np. tabelę. Tam już nic nam nie umknie 🙂
Na zakończenie wisienka na torcie. Sprawdźmy, że nasz DbContext sięgnie dane z bazy. Zamieniamy zawartość Program.cs na następującą:
using Alamakota;
using var dbContext = new ApplicationContext();
var persons = dbContext.Persons;
foreach (var person in persons)
{
Console.WriteLine(person.Name);
}
I po wydaniu komendy dotnet run powinniśmy zobaczyć: Ala Bolek Lolek
Pizza gotowa. To już wszystko na dziś 🙂
Na początek słowo wyjaśnienia. W tytule nie chodzi o Razor jako Razor Pages – wzorzec aplikacyjny, który Microsoft wprowadził przed ASP.NET MVC. Tu mam na myśli silnik Razor generujący kod html. Ten silnik jest używany w ASP.NET MVC do generowania strony z komponentów Razor. Skoro już to wyjaśniłem, to teraz gładko przechodzimy do meritum 😉
W aplikacjach webowych stronicowanie (ang. paging) przydaje się, kiedy szczodry serwer chce zasypać użytkownika duża ilością danych. Dużą, to jest taką, że wyświetlenie ich na raz mogło by tegoż użytkownika zniechęcić do zapoznania się z nimi. O ile jest to lista przyjętych na Wydział Informatyki UW, to pal sześć. Ale jeśli nasze dane to sklep internetowy z ofertą tysięcy oprawek do okularów (kto wybierał oprawki przez Internet, to wie o czym mówię ;), to aspektowi user experience trzeba poświęcić więcej uwagi. Aby strona nie była niczym zwój papirusu, to całą listę dzieli się na mniejsze kawałki i wyświetla w porcjach w nadziei, że klient łatwiej to zniesie. Stronicowanie ma też swoją praktyczną stronę. Pomaga ograniczać obciążenie łącza i źródła danych, bo kwerenda paginacji zwraca tylko tyle rekordów, ile mamy zamiar wyświetlić na stronie i ani jednego więcej.
ASP.NET Core nie oferowało paginacji „z pudełka”. I chyba nadal nie oferuje, bo samouczek Microsoftu dla .NET7 nadal pokazuje własną implementację. Jest ona o tyle pouczająca, co bardzo nieużyteczna. Implementacja w takiej postaci w aplikacji webowej oznacza każdorazowo modyfikację kodu z wielu miejscach. Dlatego proponuję wykonać pracę raz, ale w taki sposób, aby łatwo ją zastosować do dowolnej kolekcji. Wykonamy własny tag helper. Do wykorzystanie go w widoku, będzie potrzebna jedna linijka kodu.
Na początek potrzebujemy reprezentacji nawigacji do naszej listy. Będzie ona zawierała właściwości potrzebne do generowania klawiszy nawigacji.
public interface IPagination
{
int CurrentPage { get; }
int TotalPages { get; }
int PageSize { get; }
int TotalCount { get; }
bool HasPrevious { get; }
bool HasNext { get; }
}
Następnie zdefiniujemy obiekt listy. Generyczny parametr będzie można zastąpić typem odpowiednim w konkretnej aplikacji (np. GlassesFrame). Tu będzie logika odpowiedzialna za ustawienie wartości właściwości paginacji. PagedList jak na przyzwoity obiekt przystało sam zadba o utworzenie egzemplarza (linia 19, metoda Create()). Metoda bierze parametry strony (numer i ilość rekordów) oraz źródło danych jako IQueryable. Interfejs IQueryable powinien być tak zaimplementowany przez Data Provider, żeby kwerenda była generowana dopiero po zdefiniowaniu zapytania Linq i wywołaniu polecenia materializacji wyników (linia 21, polecenie Count()). Oznacza to, że Linq-to-SQL przeanalizuje wyrażenie i nie wykona przeliczenia kolekcji ściągniętej z serwera, tylko zoptymalizuje zapytanie. To serwer SQL policzy, ile mamy różnych oprawek do okularów i zwróci wartość skalarną. Napisałem „powinno”, bo to nie my mamy kontrolę nad implementacją interfejsu, a dostawca Data Providera. My możemy tylko liczyć, że kontrakt (interfejs) będzie wykonany. Spokojnie, jeśli to będzie Entity Framework, to nie mamy czego się obawiać ;). Z wywodu można wysnuć wniosek (prawidłowy), że nie ma jednego Linq. Linq zależy od źródła danych, na którym operuje wyrażenie. To jest klasa PagedList
using System.Collections.Generic;
using System.Linq;
public class PagedList : List, IPagination where T: class
{
public int CurrentPage { get; }
public int TotalPages { get; }
public int PageSize { get; }
public int TotalCount { get; }
public bool HasPrevious => CurrentPage > 1;
public bool HasNext => CurrentPage < TotalPages;
private PagedList(IEnumerable items, int count, int pageNumber, int pageSize)
{
TotalCount = count;
PageSize = pageSize;
CurrentPage = pageNumber;
TotalPages = (int)Math.Ceiling(count / (double)pageSize);
AddRange(items);
}
public static PagedList Create(IQueryable source, int pageNumber, int pageSize)
{
var count = source.Count();
var items = source
.Skip((pageNumber - 1) * pageSize)
.Take(pageSize)
.ToList();
return new PagedList(items, count, pageNumber, pageSize);
}
}
Było już o tym, że obiekt PagedList, sam policzy sobie wartości potrzebne do generowania stronicowania (CurrentPage, HasPrevious itd). Wrócimy do tego, skąd bierze potrzebne do tego informacje? Na razie wiemy, że przechowuje swój stan. Skoro tak, to możemy użyć go do przygotowania customowego Tag helpera. Robi się to w obiekcie dziedziczącym po abstrakcyjnej klasie TagHelper. W aplikacjach MVC dużą rolę odgrywają konwencje. Dotyczy to także mapowania atrybutów tagu z kodzie html na właściwości obiektu tag helpera. Nie ma silnego typowania, różne języki, trzeba sobie jakoś radzić… Wywołanie tag helpera będzie wyglądało tak:
Obiekt tag helpera (z grubsza, bo wyciąłem to co w tym momencie zbędne) wygląda tak, jak niżej. Łatwo się zorientować, że nazwa tagu to pierwszy człon nazwy obiektu PagingTagHelper, a atrybuty są mapowane na właściwości. W ten sposób kiedy proces renderujący stronę natrafi na tag , to utworzy instancję PagingTagHelper i zainicjuje właściwości wartościami atrybutów tagu.
Potem uruchamiana jest metoda Process(), ktora w kolejnych krokach buduje obiekt TagHelperOutput. Jeden z tych kroków pokazuje listing poniżej. Obiekt TagHelperOutput zawiera właściwość TagHelperContent:Content, która z kolei ma metodę rozszerzającą AppendHtml(). Budowanie htmla polega na wywoływaniu metody AppendHtml() przyjmującej enkodowany html. Metodę AppendHtml() wywołuje się wielokrotnie 'doklejając’ kawałki htmla. Na zakończenie metoda Process() zwraca wynik do silnika Razor. W ten sposób kolejno budowane są klawisze nawigacji.
private void BuildPageButtons(int pageNumber, int totalPages, TagHelperOutput output)
{
if (totalPages < 8)
{
for (var i = 1; i <= totalPages; i++)
{
BuildPageButton(pageNumber, i, output);
}
}
else
{
BuildSpacerButton(Pagination.HasPrevious, output);
for (var i = Math.Max(1, pageNumber - 2); i <= Math.Min(totalPages, pageNumber + 2); i++)
{
BuildPageButton(pageNumber, i, output);
}
BuildSpacerButton(Pagination.HasNext, output);
}
}
Powyżej jest kod jednej z prywatnych metod naszego tag helpera, pokazująca jak budowany jest kod html. Metoda generuje przyciski z numerami stron 1, 2 do 7 Jeśli stron jest więcej niż 7, to widać tylko 7 numerowanych klawiszy i symbol … Efekt wygląda tak:
Dla pierwszej strony klawisze nawigacji po lewej stronie są nie aktywne
Jeśli jest więcej niż 7 stron, to generowany jest symbol …
Klasa PaginationTagHelper wyposażona jest oczywiście w konstruktor i przeznaczona do pracy z kontenerem Dependency Injection. LinkGenerator jest dostępny automatycznie i udostępniany w przestrzeni nazw Microsoft.AspNetCore.Routing. Natomiast domyślną implementację IHttpContextAccessor należy zarejestrować services.AddSingleton(); Tag helper trzeba zaimportować do widoków dyrektywą @addTagHelper (najczęściej robi się to w pliku '_ViewImports.cshtml’). Cały kod jest poniżej:
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Mvc.Rendering;
using Microsoft.AspNetCore.Razor.TagHelpers;
using Microsoft.AspNetCore.Routing;
public class PaginationTagHelper : TagHelper
{
private IPagination Pagination { get; set; }
public string FirstPageText { get; set; } = "First";
public string LastPageText { get; set; } = "Last";
public string Controller { get; set; }
public string Action { get; set; }
private readonly LinkGenerator _linkGenerator;
private readonly IHttpContextAccessor _contextAccessor;
public PaginationTagHelper(LinkGenerator linkGenerator, IHttpContextAccessor contextAccessor)
{
_linkGenerator = linkGenerator;
_contextAccessor = contextAccessor;
}
public override void Process(TagHelperContext context, TagHelperOutput output)
{
BuildMainTag(output);
BuildFirstLastPageButton(FirstPageText, 1, Pagination.CurrentPage == 1, output);
BuildFirstLastPageButton(@"«", Pagination.CurrentPage - 1, Pagination.CurrentPage == 1, output);
BuildPageButtons(Pagination.CurrentPage, Pagination.TotalPages, output);
BuildFirstLastPageButton(@"»", Pagination.CurrentPage + 1, Pagination.CurrentPage == Pagination.TotalPages, output);
BuildFirstLastPageButton(LastPageText, Pagination.TotalPages, Pagination.CurrentPage == Pagination.TotalPages, output);
}
private static void BuildMainTag(TagHelperOutput output)
{
output.TagName = "ul";
output.Attributes.Add("class", "pagination");
output.Attributes.Add("aria-label", "Stronicowanie");
}
private void BuildFirstLastPageButton(string pageText, int pageNumber, bool disabled, TagHelperOutput output)
{
var li = new TagBuilder("li");
li.Attributes.Add("class", disabled ? "page-item disabled" : "page-item");
li.Attributes.Add("aria-label", pageText);
li.TagRenderMode = TagRenderMode.StartTag;
output.Content.AppendHtml(li);
var path = _linkGenerator.GetPathByAction(_contextAccessor.HttpContext, Action, Controller, new {pageNumber, pageSize = Pagination.PageSize});
var link = $@"{pageText}";
output.Content.AppendHtml(link);
output.Content.AppendHtml("");
}
private void BuildPageButtons(int pageNumber, int totalPages, TagHelperOutput output)
{
if (totalPages < 8)
{
for (var i = 1; i <= totalPages; i++)
{
BuildPageButton(pageNumber, i, output);
}
}
else
{
BuildSpacerButton(Pagination.HasPrevious, output);
for (var i = Math.Max(1, pageNumber - 2); i <= Math.Min(totalPages, pageNumber + 2); i++)
{
BuildPageButton(pageNumber, i, output);
}
BuildSpacerButton(Pagination.HasNext, output);
}
}
private void BuildPageButton(int pageNumber, int buttonNumber, TagHelperOutput output)
{
var li = new TagBuilder("li");
li.Attributes.Add("class", buttonNumber == pageNumber ? "page-item active" : "page-item");
li.Attributes.Add("aria-label", buttonNumber.ToString());
li.TagRenderMode = TagRenderMode.StartTag;
output.Content.AppendHtml(li);
var path = _linkGenerator.GetPathByAction(_contextAccessor.HttpContext, Action, Controller, new {pageNumber = buttonNumber, pageSize = Pagination.PageSize});
var link = $@"{buttonNumber}";
output.Content.AppendHtml(link);
output.Content.AppendHtml("");
}
private static void BuildSpacerButton(bool isVisible, TagHelperOutput output)
{
const string span = @"...";
if (!isVisible) return;
var li = new TagBuilder("li");
li.Attributes.Add("class", "page-item disabled");
li.Attributes.Add("aria-hidden", bool.TrueString);
li.TagRenderMode = TagRenderMode.StartTag;
output.Content.AppendHtml(li);
output.Content.AppendHtml(span);
output.Content.AppendHtml("");
}
}
To już prawie koniec, ale cały czas nie mamy danych, które będą stronicowane. To niedopatrzenie rozwiązuje się w warstwie aplikacji odpowiedzialnej za persystencję danych. Tam budujemy PagedList w oparciu o dane z kontrolera (pageSize, pageNumber) i dane z bazy.
public PagedList GetFrames(int pageSize, int pageNumber)
{
var frames= _productManager.GlassesFrames
.Include(x => x.GlassesFramesSizes)
.ThenInclude(x => x.Sizes);
return PagedList.Create(frames, pageNumber, pageSize);
}
Taki tag helper jest w pełni funkcjonalny. Wrożenie jest błyskawiczne. Potrzebny jest plik z kodem interfejsu i klasy PagedList oraz plik z klasą PaginationTagHelper oraz rejestracja jednego serwisu i zaimportowanie tag heplera. Wykorzystanie w kodzie to jedna linijka przytoczona już wyżej w tekście.
Miłego kodzenia 🙂
Repozytorium z przykładową aplikacją wykorzystującą PaginationTagHelper: github
Dziś o kopiowaniu. Tyle, że nie o kopiowaniu czyjegoś kodu, czego nie zalecam robić bez zrozumienia, bo można sobie/klientowi/pracodawcy zrobić krzywdę. Będzie o kopiowaniu plików. Kopiowanie plików jak wiadomo nie jest operacją, przez którą mielibyśmy nie spać. NET zapewnia zgrabne metody w statycznych klasach File czy Directory. Dodajemy sobie przestrzeń System.IO i już możemy kopiować do woli.
File.Copy("stąd", "tam")
Jeśli chcemy być bardziej profi, a na naszym pliku wykonujemy więcej niż jedną operację, na przykład chcemy do jakiegoś pliku dopisywać nową linijkę upamiętniającą nowego SMSa, którego Romek napisał do Ali, to możemy utworzyć obiekt new FileInfo("smsy-romka.txt") i używać go do tego celu. Będzie się to odbywało nieco szybciej i fajniej (czyt. profesjonalnie).
Schody zaczną się, kiedy zamiast tekstowych SMSów będziemy chcieli skopiować zdjęcia ważące po kilka MB jedno, które Romek zrobił na spacerze, a miał Romek dużą kartę pamięci i trochę czasu. Wtedy może to potrwać dłużej. Całkiem nam się humor popsuje, jeśli pliki trzeba będzie przesyłać przez sieć, nie w obrębie jednej maszyny. Wtedy najwolniejszym ogniwem nie będzie nasz dysk, tylko wydajność sieci, a z tą bywa różnie.
Takim kopiowaniem, jak pokazałem powyżej zablokujesz wątek. Jeśli jest to wątek UI, to aplikacja stanie się „trudna w kontakcie” lub inaczej mówiąc nie responsywna i może się okazać, że nawet nie da się jej zamknąć (WinForms). Sprytnie możesz przekazać taki przydługi proces do wykonania w tle w wątku pobranym z puli, a wątek główny może w tym czasie wykonywać inne zadania, jakie dla niego wymyślimy, albo obsługiwać interfejs użytkownika.
var copyTask = Task.Run(() => File.Copy("stąd", "tam"));
Kopiowanie plików wykonywane przez OS „pod spodem” .NET jest asynchroniczne. Dlatego zatrudnienie nowego wątku niczego nie polepszy, jeśli Task.RunI() zastosujemy w kodzie asynchronicznym. Taki trik ma sens tylko, jeśli znajdzie się w kodzie wykonywanym przez główny wątek aplikacji.
Trzeba poczekać na zakończenie tego Tasku wydając komendę: await copyTask. Po dojściu do await, wątek główny przejdzie do innych zadań. I jeśli jest to aplikacja webowa lub okienkowa, to natychmiast docenimy zalety naszego posunięcia, bo aplikacja przestanie „lagować”. W wypasionej wersji można nawet przekazać CancellationToken, aby skończyć z takim Taskiem, gdyby oczekiwanie znudziło usera i postanowił zamknąć aplikację.
Jest jednak jeden problem. Po zamknięciu aplikacji przed zakończeniem kopiowania system plików zostawi nam w docelowej lokalizacji plik z przypadkową zawartością. Na dodatek zaalokuje miejsce na dysku. Romek nawet nie będzie wiedział, że stracił swoje zdjęcie!
Aby temat ogarnąć tak, żeby wstydu nie było, wypadało by zrobić dwie rzeczy:
Zadanie kopiowania wykonać asynchronicznie, ale tak, żeby ewentualny shut down aplikcji dał nam czas na zwolnienie zasobów i posprzątanie, zanim ostatecznie aplikacja zostanie zamknięta.
Posprzątanie pozostałości po przerwanym zadaniu.
Do pierwszego punktu użyjemy klasy FileStream, która zawiera asynchroniczną metodę CopyToAsync. Nie będziemy oryginalni i użyjemy tej metody. Czyli kopiujemy tak:
async Task CopyFileAsync(string sourcePath, string destinationPath)
{
var sourceStream = new FileStream(sourcePath, FileMode.Open, FileAccess.Read);
var destinationStream = new FileStream(destinationPath, FileMode.CreateNew, FileAccess.Write);
await sourceStream.CopyToAsync(destinationStream);
}
Kod jest uproszczony, aby był przejrzysty. Pełny działający kod można znaleźć na Githubie. Link znajduje się pod artykułem.
Jest prawie super, ale musimy rozwiązać temat sprzątania po ewentualnym przerwaniu kopiowania. Poprawiona wersja wygląda tak:
async Task CopyFileAsync(string sourcePath, string destinationPath, CancellationToken cancellationToken)
{
try
{
var sourceStream = new FileStream(sourcePath, FileMode.Open, FileAccess.Read);
var destinationStream = new FileStream(destinationPath, FileMode.CreateNew, FileAccess.Write);
await sourceStream.CopyToAsync(destinationStream, cancellationToken);
}
catch (OperationCanceledException)
{
var cts = new CancellationTokenSource();
cts.CancelAfter(TimeSpan.FromSeconds(3));
await Delete(destinationPath, cts.Token);
}
catch (Exception)
{
using var cts = CancellationTokenSource.CreateLinkedTokenSource(cancellationToken);
cts.CancelAfter(TimeSpan.FromSeconds(10));
await Delete(destinationPath, cts.Token);
throw;
}
}
Po pierwsze, asynchroniczna metoda CopyToAsync przyjmuje CancellationToken, więc korzystamy z tego natychmiast i przekazujemy do niej token (linia 7).
Po drugie, w linii 9 przechwytujemy OperationCanceledException i czas jaki mamy na zamkmięcie procesu wykorzystujemy na skasowanie pliku, który został utworzony w docelowej lokalizacji, ale na pewno będzie uszkodzony, bo przecież kopiowanie zostało przerwane. W tym celu tworzymy nowy token, który daje metodzie Delete() trzy długie sekundy z pięciu jakie defaultowo dostaje aplikacja na zamknięcie (linia 12).
Po trzecie, w przypadku innego błędu także kasujemy plik, który najprawdopodobniej będzie uszkodzony, ale dodatkowo rzucamy wyjątek do kodu wywołującego kopiowanie. Niech go sobie obsłuży (linia 20).
W ten sposób kopiowanie nawet dużych plików może odbywać się bez utraty responsywności aplikacji, a ewentualne błędy nie powodują śmietnika w systemie plików. Kod, który jest na Githubie dodatkowo pilnuje cyklu życia egzemplarzy FileStream. Ma też zaimplementowaną flagę overvrite i ma dodatkową metodę MoveFileAsync.
W każdym kodzie znajdzie się coś do poprawienia. Nie inaczej jest w tym przypadku. Plik po zapisaniu w nowej lokalizacji powinien być zweryfikowany na okoliczność zgodności z oryginałem. Można to zaimplementować przez obliczenie skrótów oryginału i kopii i porównaniu ich wartości. Jeśli nie są zgodne, to coś poszło nie tak i należy taki przypadek obsłużyć.
Uwaga na koniec
Z punktu widzenia aplikacji .net metoda File.Copy wykona się synchronicznie i kod wywołujący File.Copy rzeczywiście na chwilę spauzuje. Jednak operacje I/O są asynchroniczne na poziomie systemu operacyjnego. Co więcej, aplikacja wykonująca się pod kontrolą Windows nawet nie otrzymuje danych do kopiowania. .net przesyła do systemu informacje o pliku i reszta odbywa się już bardzo szybko na poziomie systemu. Zatem możesz spokojnie stosować synchroniczne komendy np. File.Copy w swoim kodzie.
Kiedy wobec tego stosować kopiowanie asynchroniczne?
Roważ to rozwiązanie kiedy
pliki są duże
aplikacja ma UI i obsługa kopiowania może wpłynąć na płynność interfejsu